
OpenWGA 7.6 - OpenWGA Concepts and Features
Basic artefacts and termsContent Stores
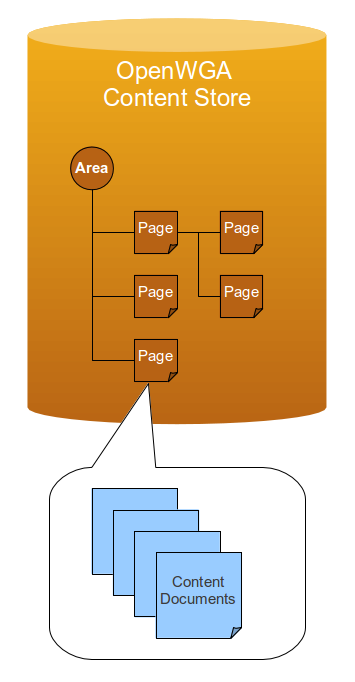
The OpenWGA content store is the ("real") database of a web application where all content data is stored. It has a predefined schema that organizes it in the following way:
Most data in an OpenWGA content store is organized in so called documents that logically group data.
The real content data is organized in website areas. Each area contains the content for a special section of the application. Using areas to organize the data is up to the editor of the app. Many apps only have a single area which is mostly named "home".
Each website area owns a page hierarchy. This is - as the name says - a hierarchy of "pages" where each page contains the data of a single "page of the website" or a "record of data", depending on what you are actually building. Organizing this hierarchy is again up to the content editor, but OpenWGA expects it to represent the "navigational structure of the site" in any senseful way. So the pages at the root of the hierarchy may represent website categories while the documents below them contain the articles contained in the category.
The page itself does not hold the real data. This is because the content data for a single page may be available in various languages and versions. Therefor a page consists of an unlimited number of so called content documents. A single content document represents the data of the page for a special language and version. For each language only one version of a content document may be published at a time. See an overview of content documents and their lifecycle on a page on content versioning and workflows.
The data on the content document
The data on a content document is organized the following way: Fields called items store the actual (non-binary) content data. A content document may contain an infinite number of custom items identified by their name. In OpenWGA these items are not limited by any kind of schema.
The content document is also capable of storing binary data in the form of file attachments. These attachments closely resemble those file attachments that you can attach to E-Mails, only that here they are attached to a document. A content document may hold an infinite number of those that are identified by their file name.
Other special fields are called metadata fields. These are predefined fields that describe the content document, its state and behaviour. Important metadata fields are the title and description whose contents is determinable by the author, but also version and status which are readonly and managed by the CMS. See the list of available content metadata fields on the content document definition.
Last not least a content document may store relations to other pages. A relation has a name just like an item, but instead of a value it points to a different page. Just like the name implies content relations are used to define any functional relation between two pages, for example when a content document uses a relation to point to a template document it case created from.
See the following illustration of the data organisation on the content document:
