
OpenWGA 7.10 - OpenWGA Concepts and Features
Administration » Features » Lucene fulltext indexConfiguring individual indexing of web apps
On the web app configuration of every app in OpenWGA admin client there is a tab labeled "Fulltext configuration" which controls, how OpenWGA indexes the contents of the content store of this app in lucene fulltext index. On up-to-date OpenWGA content stores (CS version 5 patch level 5 or higher) it looks like this:
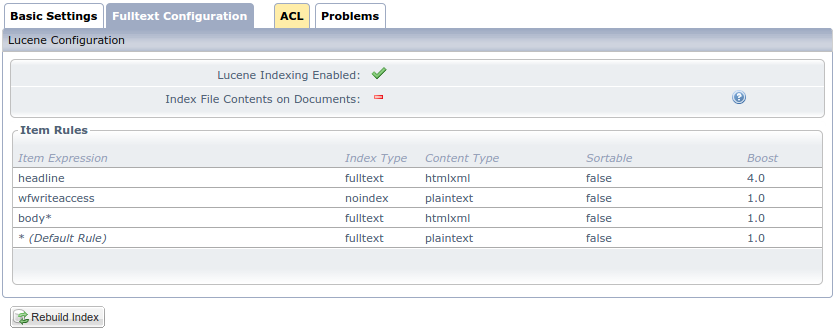
It consists of the following parts:
- The flag Lucene indexing enabled controls generally if lucene is going to add the content of this content store to the index
- The flag Index file contents on documents activates a legacy functionality for indexing file attachments. It controls if contents of file attachments will also be indexed on index entries of doctype "content", so they will be found on field-unspecific queries when their attachments match the query. This equals the flag "Include in allContent" on the legacy fulltext configuration (see below) and should not be enabled if the application already handles direct file attachment matches of SEARCHDOCTYPE "attachment" (see Finding matches in file attachments). Otherwise this could result in some document appearing twice in search results.
- The Item rules define rules for indexing items on content documents. Per default there is one rule "*" matching all items which indexes every item as index type "fulltext", but you can specify multiple rules which will match individual item names. The first rule whose "Item Expression" matches an item name will be used to index that item. The fields of each rule in detail:
- The Item Expression is used to match the item names where this rule should apply. It either is a concrete item name, the beginning of an item name suffixed with the wildcard "*" matching all item names beginning with the given term or only "*" which denotes the default rule
- The Index type controls how the contents of this item is stored on the index and therefor how it can be queried:
- fulltext: The field value is analyzed and tokenized, i.e. its contents is divided up in individual word tokens that are indexed in a normalized form. It can be found querying for any single word token in the contents. Use this for items that should be really queried in a "fulltext" manner where you want to find documents where a certain word appears somewhere in its contents.
- keyword: The complete field value is stored unmodified and -analyzed, therefor only can be found when querying for the exact and complete contents of the field. Use this for fields where you want to query for exact field contents, like type denominators or any other kind of "hard" data.
- noindex: The field is not indexed.
- The content type identifies if the contents of the item is HTML or XML markup, which will make lucene only index the real text contents and not the text, or if it is plain text that will be index completely.
- The field sortable identifies if Lucene should also sorting of query results based on this field
- The field boost denotes the relevance of matches in this item. Normally this is 1. Setting it to a higher value will raise the search score of matches that are found in this item relative to those found of items with lower boost.
- The button Rebuild index completely re-indexes all contents on this database. Be aware that this first discards all old index entries, so your application may not work as expected regarding fulltext queries until the index is completely rebuild. Also be aware that this might be a very time consuming task, depending on the amount of contents in this content store.
If you have a content store of lower version than 5 at patch level 5 then this editor displays the legacy fulltext configuration, looking like this:
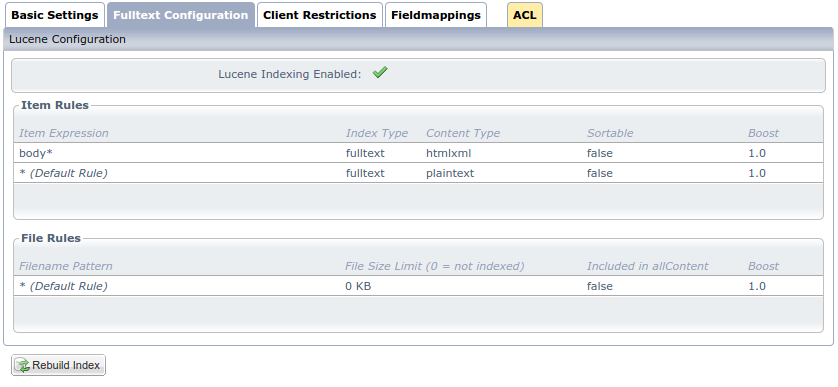
It features a separate list of file rules that were obsoleted with the new file attachment indexing functionality introduced in OpenWGA 7.1. Here it is possible to denote separate rules for attachments based on their filename, also to determine a maximum size that attachments may have to let them be indexed. The field "Included in allContent" equals the new option "Index file contents on documents", but on a per rule base. The boost has the same meaning as on item rules. Those file rules were obsoleted as it has proven to be impractical to differ file indexing behaviour based on the file name, which is not under the control of an app.